本文包含机器学习理论,再到机器学习编程框架工具,最后介绍相关的实战案例
机器学习 & 深度学习
机器学习、深度学习三个部分:模型、损失函数、优化算法
常见损失函数
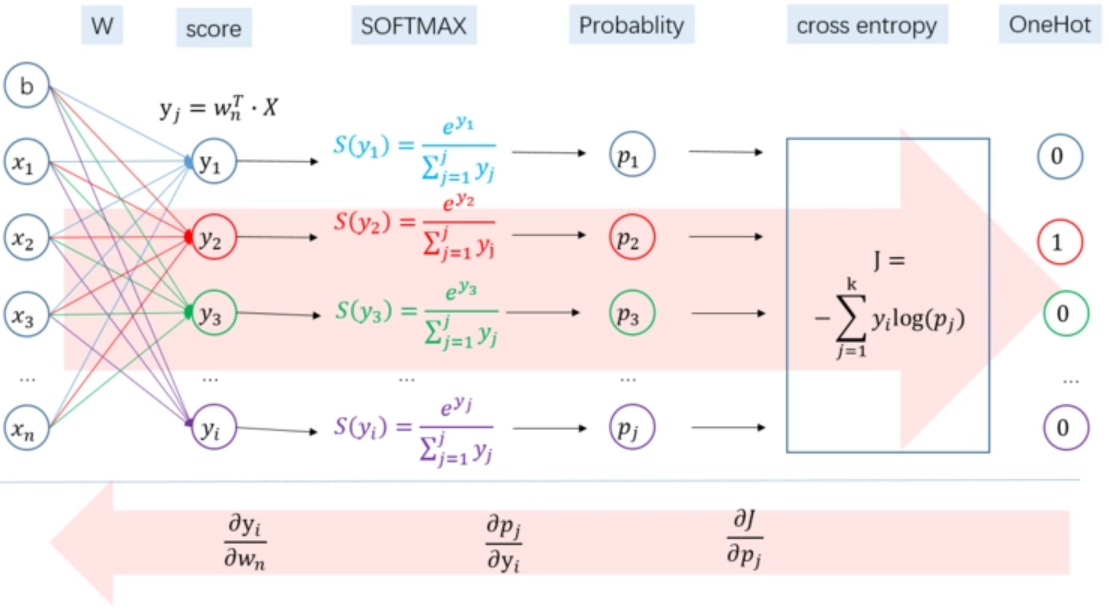
- softmax_cross_entropy用于在二分类或者类别相互排斥的多分类任务中。
- binary_cross_entropy是二分类的交叉熵,实际是多分类softmax_cross_entropy的一种特殊情况,当多分类中,类别只有两类时,即0或者1,即为二分类,二分类也是一个逻辑回归问题,也可以套用逻辑回归的损失函数(sigmoid_cross_entropy)。
- sigmoid_cross_entropy用于类别独立且不相互排斥,可以执行多标签分类,如图片可以同时包含大象和狗。
梯度下降算法优化器
- Momentum优化器:由于波谷容易来回震荡;引入上一轮的动量(一阶矩估计),加速收敛,抑制震荡。其中$\lambda$是学习率,g是原始梯度,$\beta$是动量m的衰减系数,通常为0.9。
- 自适应优化器AdaGrad:有的参数更新很快,有的更新很慢,例如word2vec中常见词和生僻词的参数更新;为了尽可能保持参数更新步调一致,每个梯度除以它的历史梯度平方累加和的平方根(二阶矩估计),大的梯度缩小,小的梯度放大。
- RMSprop优化器:AdaGrad优化器分母是递增的,会导致梯度提前减小到0,因此RMSprop只考虑最近几轮迭代中的梯度,利用指数加权平均的方法来计算二阶矩估计,指数级地缩小最早的梯度。
- Adam优化器结合一阶矩估计和二阶矩估计,都是用指数加权平均。
由于在训练的时候m初始值为0,会导致$m_t$偏向于0。所以,需要对梯度均值m进行偏差纠正,降低偏差对初始值的影响。同理$\gamma$也需要偏差纠正。新的公式1如下:

TensorFlow基本概念
数据流图:有向边和节点
节点:数据节点(输入)、计算节点、存储节点(参数)
张量:数学上是几何体,0阶表示标量,1阶是向量,二阶是矩阵;
在TensorFlow中张量是相同数据类型的多维数组,是操作的输入和输出数据。
张量包含:常量、占位符(运行时确定)、变量
会话:是将数据流图提交到执行器上的client。
数据流图中入度为0的节点会被执行,并可以在不同设备上并行执行。
TensorFlow编程流程
定义模型输入输出
定义模型数据流图,即模型
运行数据流图会话
保存变量:tf.train.Saver.save() # 保存模型训练的参数到文件中(checkpoint)
恢复变量:tf.train.Saver.restore()
TensorBoard可视化输入数据、训练参数、评价指标等。
tf.summary读写需要可视化的数据
tf.name_scope定义名字作用域,划分数据流图不同节点
dataframe.info() # 显示pandas数据信息
Keras常用命令
model=Sequential()定义模型
model.compile()编译模型
model.fit()训练模型
model.save()保存模型为HDF5文件
model.sumary()查看模型网络结构、参数个数
model.history模型训练过程中的关键指标记录
卷积神经网络
convolutional layer利用输入数据中特征的局部性和位置无关系来降低数量并提取局部特征。
pooling layer
dropout layer是一种正则化层,每一轮训练的时候随机关闭一些神经元,不进行更新;测试的时候所有神经元都是用的。
Flatten()层多维数据转换为一维数据
python & numpy & matplot
np.nonzero() # 保留非0数据
np.astype(‘float32’) # 类型转换
str.lstrip(‘’) # 左边特定字符串替换为空
plt.xticks([]) # 清空绘图坐标轴
plt.yticks([])
实战案例

验证码识别
Jupyter交互式开发环境
captcha验证码生成库
pillow图片读写库
pydot图片格式转换库
Flask轻量级web应用框架
数据处理流程
输入转灰度图后归一化
input_shape与channels_last
输出标签one-hot编码
1. mathjax公式编辑器常见语法 ↩